
DKABio的健康分數是怎麼算的?
我用HS 來表示DKABio所建置的健康分數或指標。HS指標建置的基本概念與體弱指標(Frailty Index,FI)建置的概念有些類似,儘管兩者在許多方面有著不同之處。
一方面,FI 和 HS 均應用非常相似的數據變量: 包括人口統計信息、主觀健康評估、家庭和自身疾病信息、社會行為、實驗室尿液和血液標誌物等。
差別是: 我所知道的FI 的建置應用了35 個生理生化變數,而HS指標的計算則是使用了 148 個生理生化變數(實際應用時,32個特別選擇的變數效果也很好),這些變量主要由台灣的健康管理機構在 2000 年至 2016 年間從約 450,000 名 20 歲及以上的參與者中收集(稱為數據 A),每個參與者的平均觀察時間約為 3.6 年。
HS 指標的建置使用了強大的機器學習技術來開發指標的基本分層結構 ,也就是「DKABio分層」,這種分層結構對於未來疾病的風險預測也扮演很重要的技術角色。
下表提供男女各6個分層未來10年內的疾病風險值,共有15種疾病列入分析,資料來源是台灣健保資料庫。
除了很少數的例外,我們發現風險值一般會隨分層水準的遞增而遞減,有些例外通常發生在男性第5層和第6層之間的比較;
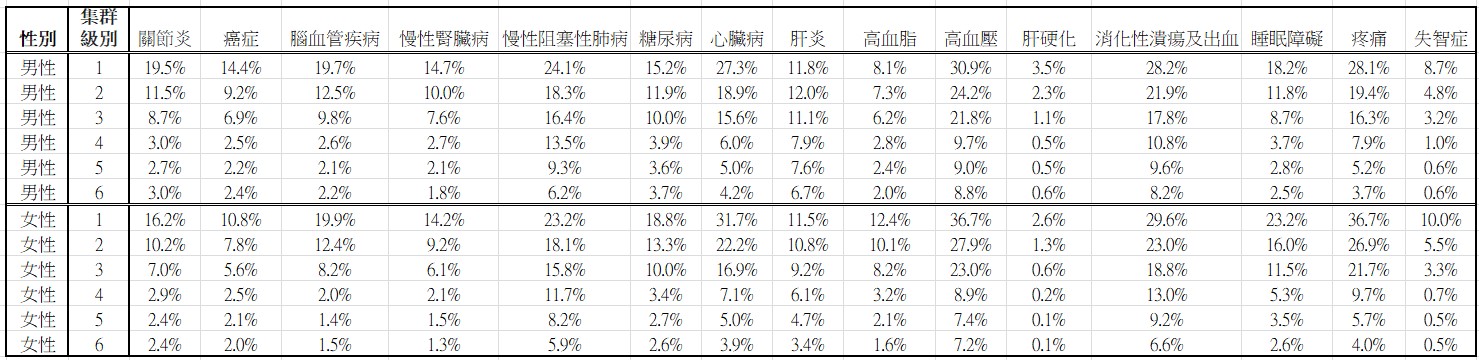
15種疾病或症狀10年內的風險值
若是我們將年齡因素加入也當成分層的基礎,這種例外的現象就會消失;篇幅的關係,這些討論省略掉了。
最終的發現是: 分層水準越高年紀越輕,各種疾病的風險就越小,反之,分層水準越低年紀越老,各種疾病的風險就越高。
DKABio主要是將年齡和DKABio的分層結果當成風險因子來建立指標。 為了完成DKABioHS指標的建置,最後的大數據演算法要決定的就是這個人是屬於何等分層水準?或者更廣義的說是: 屬於各種分層水準的機率各有多少?
我們在給定各別分層水準一定的分數之後,個人DKABioHS的指標值就是以個人的機率值為權數的平均分數。
數據A結果顯示, 所有女性/男性的HS 範圍是: 16.7-85 / 13-88。我們證明了 HS 是一種具有一致性特質的健康分數,因為訓練樣本和驗證樣本所得出的健康分數差異非常小,「平均絕對誤差百分比」 都在 1.2-1.6 % 之間,顯示HS 是一種非常穩定的指標。特性是: 較高的 HS 表示健康狀況較好或疾病風險較低,但會隨著年齡或疾病數量的增加而降低。
使用 HS,我們自然的定義了一個「疾病地圖」來區分患病(HS<60)和未患病的人(HS>=60)。經過和年齡、性別有關的條件設定,還可以將非疾病人群區分為一般健康人群和亞健康人群,從而可以採取不同的健康管理來預防疾病。
條件設定的原則是亞健康人群的疾病風險約是一般健康人的兩倍,所以我們身體亞健康人的定義是建立在很明確的風險倍數的基礎上;這種作法只有應用大數據的結果才能達成。
數據A的實證結果顯示,被歸類為亞健康人群的疾病風險遠高於一般健康人群,女性/男性5年內罹患至少一種疾病的風險分別為29% VS 15% / 29% VS 16.5% 。
DKABioHS就像一個可以顯示長期驅勢的綜合指標,可以精準的描述自身健康的整體狀態;借由和其他人HS的結果比較,可以認識自己身體健康管理的相對表現。
它給我們機會自我評估身體是否要繼續走這一條自己無意間或者是刻意走出來的路徑。
|
|
鄭光甫 首席顧問 醫學經歷:臺北醫學大學生物統計研究中心主任、公衛學系講座教授; 中國醫藥大學生物統計中心講座教授兼主任、健康照護學院院長、公衛學院院長;美國哈佛大學公衛學院客座教授
|
