
Hugging Face自然語言處理的強大助力 醫療對話模型入門指南

目錄
Hugging Face 不僅僅是一個表情符號,它是一個開源的資料科學和機器學習平台。它扮演著人工智慧專家和愛好者的匯聚地 - 就像是人工智慧領域的 GitHub。
簡介 Hugging Face 人工智慧的開源綠洲
Hugging Face 是一家創立於 2016 年的人工智慧公司,總部位於美國紐約市。由Clement Delangue、Julien Chaumond 和 Thomas Wolf 共同創立。
Hugging Face 最初於 2017 年作為青少年的聊天機器人應用程式推出,經過多年的發展,可以在其中託管自己的 AI 模型、對其進行訓練並與您的團隊合作,通過提供開源工具和資源,讓開發者更容易地訓練、部署和分享自然語言處理模型,從而促進人工智慧在自然語言處理領域的應用和發展。
在 Hugging Face 的帶領下,自然語言處理技術取得了巨大的進步,許多先進的模型和算法被廣泛應用於各種應用場景中,如文本分類、機器翻譯、問答系統等。Hugging Face 的開源精神和技術貢獻在整個自然語言處理領域中都得到了高度的認可與關注,成為了這個領域不可或缺的一部分。
由於人工智慧「我們沒有護城河」的氛圍,這時候 Hugging Face 就變得特別關鍵了。沒有一家大科技公司能獨立解決所有的人工智慧難題,這就是 Hugging Face 的初衷:提供工具,讓盡可能多的人參與塑造未來的人工智慧工具。
降低開發門檻
Hugging Face 提供了易於使用的工具和模型,使開發者能夠快速上手 NLP,無需投入大量時間和精力。
促進創新
Hugging Face 提供了一個開放的平台,鼓勵開發者分享和交流成果,促進 NLP 技術的創新和發展。
加速應用
Hugging Face 使得 NLP 技術更容易應用於實際場景,推動了各行各業的智慧化升級。
Hugging Face 介面有些甚麼?如何使用?
在自然語言處理領域,模型和數據的共享是推動創新和發展的關鍵; Hugging Face作為一個開源平台,旨在促進模型和數據的共享,為大眾提供一個便捷的交流和合作的場所。
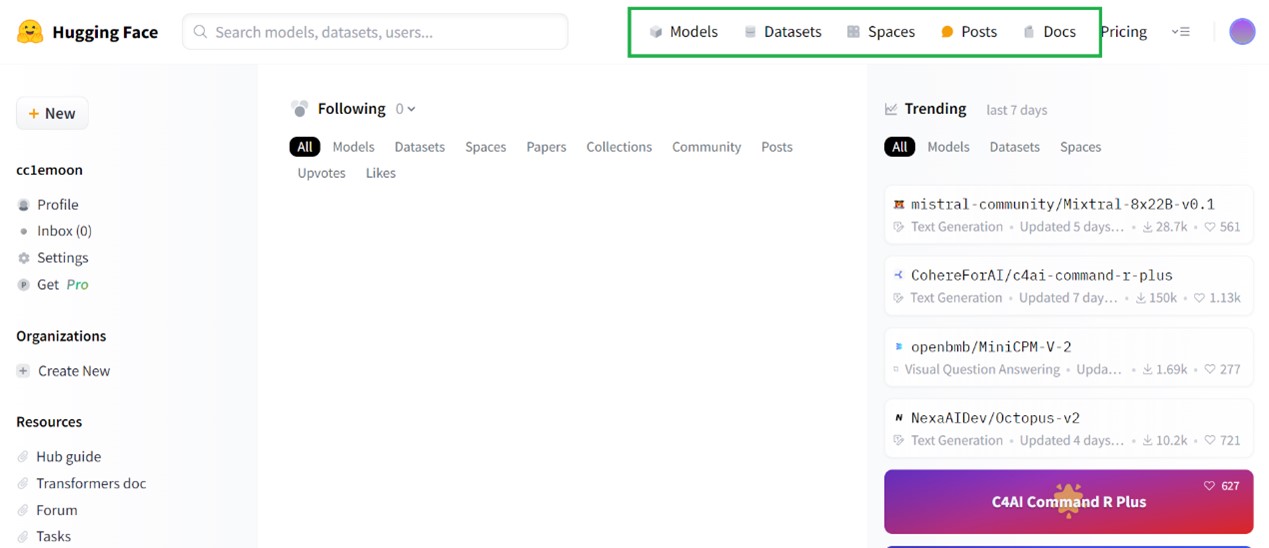
Models
Models分頁提供了 Hugging Face共享的各種模型。目前在Hugging Face上共有約61萬個模型,功能種類非常豐富,涵蓋了各種自然語言處理 (NLP) 相關的任務和應用。例如:深度估計、影像生成、文字轉影片;模型涵蓋了多個領域如經濟、醫療、生物等。可以在這裡找到並下載所需的模型,並使用它們進行相關的任務。
要訓練一個強大的人工智慧模型需要大量數據作為知識來源,同時也對運算能力有著極高的需求。近年來科技的快速發展,複雜的大型AI模型才得以誕生。
Datasets
Datasets 分頁提供了 Hugging Face 共享的數據集。這些數據集涵蓋了各種自然語言處理任務所需的文本數據,如情感分析、機器翻譯、問答等。可以在這裡找到並下載你所需的數據集,用於模型訓練和評估。
Spaces
展示基於 Hugging Face 模型與工具構建的應用示範,允許用戶創建自己的工作區或空間,用戶可以在其中組織或是使用模型。
Docs
提供了 Hugging Face 平台上各種工具和資源的使用和說明。包括了模型和數據集的使用指南、API 、教學和示範等。可以在這裡找到所需要的資訊,以便更好地使用 Hugging Face 提供的工具和服務。
Hugging Face 模型Q&A
模型「~B」的意思是甚麼?
模型名稱中的 4B、7B 等數字是指模型的參數大小(Parameters),通常以「B」表示十億(billion)的參數量。
一般來說:
- 4B 指的是模型有 40 億(4 billion)個可訓練參數
- 7B 指的是模型有 70 億(7 billion)個可訓練參數
參數量越大,代表模型的計算能力和表達能力越強,但同時也意味著模型越大、需要的計算資源越多。
例如:
- GPT-3 最大有 1750 億(175B)參數的版本
- TAIDE為台灣國科會研發的70億(7B)大型語言模型
模型參數數量通常與模型大小和能力呈正相關。研究人員會根據任務複雜度、可用計算資源等因素,選擇合適參數規模的模型。參數越多,通常意味著模型的能力越強,但訓練和推理的成本也會越高,需要綜合考慮參數量與性能、成本之間的平衡。
模型種類有哪些?甚麼差別?
1.預訓練模型(Pretrained)
預訓練模型是通過使用大規模文本數據上進行訓練。這些數據可以是書籍、文章、網頁等。在訓練過程中,模型學習語言的基礎結構和語義,例如單詞的含義、句子的結構和語法的規則 。例如 Google所開發的BERT、OpenAI 的GPT或是Meta AI推出的LLaMA,都是訓練模型的初始基礎。
2.微調模型(Fine-tuned)
微調模型是在預訓練模型的基礎上,使用特定任務的標記數據進行微調的。在微調過程中,模型學習特定任務的知識和技能,例如如何進行文本分類、情感分析或醫學影像等判斷。如台灣國科會研發的TAIDE模型,就是以LLaMA為基礎、用大量繁中資料微調而成。
3.指示調整模型(Instruction-tuned)
指示調整模型是使用自然語言指示來訓練的。指示可以是簡單的命令,也可以是複雜的說明。在訓練過程中,模型學習理解和遵循指示,並根據指示完成任務。相較於預訓練和微調模型,所需的成本較低,常見於對話式 AI 助理的訓練,提升模型按指令行事的能力。
4. RL-tuned強化學習調整模型(RL-tuned)
強化學習是一種機器學習方法,它允許代理 (agent) 與環境互動,並通過試錯來學習最佳的行為策略。在訓練過程中,模型通過嘗試不同的行為來獲得獎勵,並逐漸學習最優策略。

Hugging Face常用的工具及模型:Spaces 和 Transformers
Hugging Face 的最大優勢之一是它的便利性。即使是沒有 NLP 背景的開發人員,也可以通過 Hugging Face 提供的直觀界面和詳細的說明快速上手。使用hugging face的模型方法有許多種,其中Spaces 和 Transformers是兩個常用的工具。
Spaces 是一個簡易的平台,允許使用者在瀏覽器中使用hugging face上的模型,使用者無需編寫任何程式碼即可使用 ;Transformers 則是由 Hugging Face 開發的 Python 庫,專用於自然語言處理 (NLP)。
使用 Spaces
使用 Hugging Face 的模型最簡單方法是透過 Spaces。 Spaces 是一個簡易的互動界面,允許使用者直接輸入數據並獲得模型的結果。
Spaces也有許多醫療領域的模型,我使用BioMistral/BioMistral-7B 作為示範,BioMistral是一個專為生物醫學領域量身定制的開源 LLM,可以應用於各種醫學問題的解答任務。
Step1:開啟Hugging Face,登入或建立您的帳戶
在Spaces的介面可以瀏覽各種不同類型的模型做使用,或是搜尋有興趣的特定模型。
Step2:點擊有興趣的Space
例如BioMistral 7B chat,他是一個簡易的醫學對答模型,同時支援7種不同語言的輸入與回答。
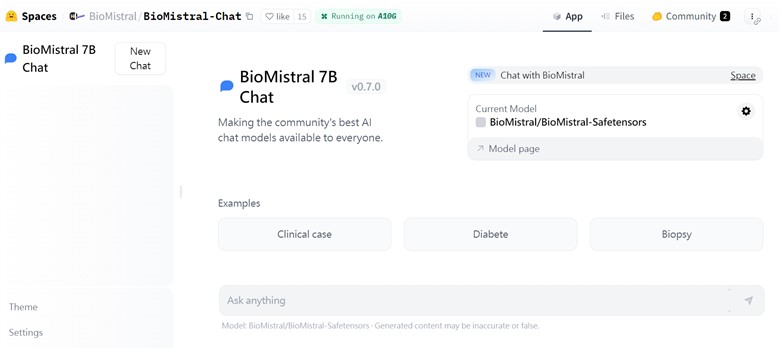
Step3:確定Space平台運行正常,即可開始使用。
舉例而言,可以輸入「描述第2型糖尿病的症狀、原因和治療方案」,就可以獲得模型在後台運行後的分析結果。

Hugging Face Transformers 使用
Hugging Face Transformers是一個強大的開源Python函式庫,提供了各種常用的預訓練模型和工具來解決自然語言處理(NLP)任務。它的易用性、全面性和高效性,使其成為NLP開發者和研究人員的首選之一。
使用johnsnowlabs/JSL-MedMNX-7B-v2.0 ,這是一個醫學領域的開源大型語言模型,在Open Medical-LLM 排行榜上表現優異;如何使用Transformers來應用這個模型呢?可以參考開發者所提供的程式碼。
步驟一:安裝套件並引入必要的模組

步驟二:準備模型和用戶訊息

步驟三:載入模型、生成文本並輸出結果

輸出結果如下:
Type 1 diabetes, also known as juvenile diabetes or insulin-dependent diabetes, is a chronic condition in which the pancreas produces little to no insulin. Insulin is a hormone that regulates blood sugar levels by allowing glucose to enter cells for energy. Without enough insulin, glucose builds up in the bloodstream, leading to high blood sugar levels.
第1型糖尿病,也被稱為幼年糖尿病或胰島素依賴型糖尿病,是一種慢性疾病,胰臟產生的胰島素少至沒有。胰島素是一種調節血糖水平的激素,它允許葡萄糖進入細胞以產生能量。如果胰島素不足,葡萄糖將在血液中積聚,導致血糖水平升高。
Type 1 diabetes is typically diagnosed in children and young adults, although it can occur at any age. It is an autoimmune disease where the body's immune system mistakenly attacks and destroys the insulin-producing cells in the pancreas. This results in a lifelong dependence on exogenous insulin for survival.
第1型糖尿病通常在兒童和年輕成人中診斷,雖然它可以在任何年齡發生。這是一種自體免疫疾病,其中身體的免疫系統錯誤地攻擊並摧毀胰臟中產生胰島素的細胞。這導致終身依賴外源性胰島素以維持生存。
Symptoms of Type 1 diabetes include frequent urination, excessive thirst, unexplained weight loss, fatigue, blurred vision, and slow-healing sores. Treatment involves managing blood sugar levels through insulin injections or an insulin pump, monitoring blood sugar regularly, following a healthy diet, and engaging in regular physical activity.
第1型糖尿病的症狀包括頻尿、過度口渴、未明原因的體重減輕、疲勞、視力模糊和傷口癒合緩慢。治療包括通過注射胰島素或使用胰島素泵來管理血糖水平、定期監測血糖、遵循健康飲食並進行定期運動。
It is important for individuals with Type 1 diabetes to work closely with healthcare professionals to manage their condition and prevent
對於患有第1型糖尿病的個人來說,與醫療專業人員密切合作,管理他們的狀況並預防是非常重要的。
Open Medical-LLM Leaderboard 醫學ai的評估排行榜

隨著大型語言模型(LLM)在醫療保健領域的應用越來越廣泛,例如針對醫學問答、患者對話和診斷推理等任務,Hugging Face平台上的各種醫學相關模型都展現出了卓越的性能和前景。然而,醫療領域對於模型的準確性和安全性要求極高,因為即使是微小的錯誤也可能對患者生命造成威脅。由於模型普遍存在的幻覺問題,LLMs所提供的信息準確性一直受到質疑。
這就是 " Open Medical-LLM Leaderboard " 的由來。由Open Life Science AI ,一個非營利組織的研究人員推出了一系列新的基準來評估醫療保健產業特定參數的模型,針對不同的醫療相關任務,建立一個客觀的基準測試平台,可以全面評估各大語言模型的能力。通過這一排行榜,醫療機構將能更精準地選擇合適的AI助手,開發商也將獲得寶貴的反饋來完善模型。
- 幫助開發人員選擇最適合其需求的 LLM。
- 推動 LLM 技術的發展。
- 提高公眾對 LLM 在醫療保健領域的潛力的信心。
Open Medical-LLM Leaderboard在spaces上就可以使用。
Open Medical-LLM的排名是基於每個模型的醫學知識和回答問題的能力。官方公告表示:「Open Medical-LLM排行榜旨在追蹤、排名和評估大型語言模型(LLMs)在醫學問答任務上的表現。它評估各種醫學資料集的LLMs,包括 MedQA (USMLE)、PubMedQA、MedMCQA 以及與醫學和生物學相關的 MMLU 子集。排行榜對每個模型的醫學知識和問答能力進行了全面評估。」
醫學模型的評估指標資料集
MedQA 資料集由美國醫療執照考試 (USMLE) 的多項選擇題組成。它涵蓋了一般醫學知識,包括開發集中的 11,450 個問題和測試集中的 1,273 個問題。每個問題有 4 或 5 個答案選擇,該資料集旨在評估美國醫療執照所需的醫學知識和推理技能。
MedMCQA 是源自印度醫學入學考試(AIIMS/NEET)的大規模多項選擇 QA 資料集。它涵蓋 2.4k 個醫療主題和 21 個醫學科目,開發集中有超過 187,000 個問題,測試集中有 6,100 個問題。每題有 4 個答案選擇,並附有解釋。 MedMCQA 評估模型的一般醫學知識和推理能力。
PubMedQA 是一個閉域 QA 資料集,其中每個問題都可以透過查看相關上下文(PubMed 摘要)來回答。它由 1,000 個專家標記的問答對組成。每個問題都附有作為上下文的 PubMed 摘要,任務是根據摘要中的信息提供是/否/也許的答案。此資料集分為 500 個用於開發的問題和 500 個用於測試的問題。 PubMedQA 評估模型理解和推理科學生物醫學文獻的能力。
MMLU 基準(測量大規模多任務語言理解)包括來自各個領域的多項選擇題。對於開放醫療 -LLM 排行榜,針對臨床知識、醫學遺傳學、解剖學、專業醫學、大學生物學以及大學醫學,評估模型對特定醫學和生物學領域的理解。
測醫學模型評比結果 醫療應用前景寬闊
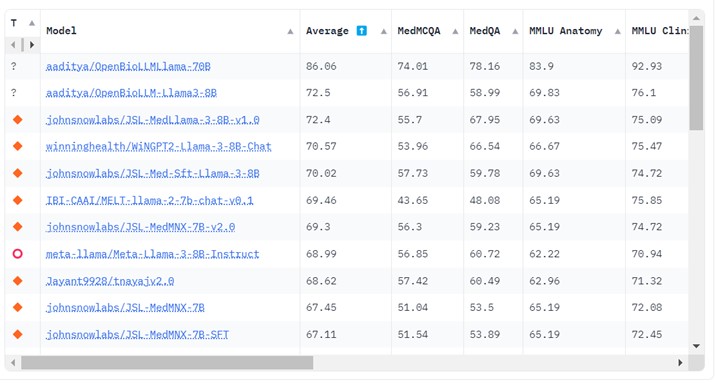
藉由Open Medical-LLM Leaderboard,我們可以評比多個大型語言模型在醫學問答任務上的效能。結果顯示,商業模型如GPT-4-base和Med-PaLM-2在多個醫學領域中取得了優異的成績,證明了它們在處理醫學相關問題上的強大能力。
此外,即使參數量較少,開源模型如Starling-LM-7B、gemma-7b、Mistral-7B-v0.1和Hermes-2-Pro-Mistral-7B也在特定的數據集和任務中展現了優異的表現。 商業模型在解讀科學生物醫學文獻以及運用臨床知識進行決策的能力上都有良好的表現,尤其是在PubMedQA和MMLU臨床知識子集等專業任務上。
Google的Gemini Pro模型在生物統計學、細胞生物學和婦產科等數據密集型和程序性任務上表現尤為突出。然而,在解剖學、心臟病學和皮膚科等關鍵領域,其表現僅達到中等水平,顯示出在全面醫學應用方面仍有改進的空間。
總體來說,這些發現強調了大型語言模型在醫學領域應用的潛力,同時也指出了需要進一步研究和開發的領域。
Hugging Face 作為NLP領域的重要平台,為開發者和研究人員提供了方便快捷的模型分享和部署方式。透過Hugging Face ,任何人可以輕鬆使用模型和相關資源,加速了NLP技術的發展和應用。特別是在醫學領域,NLP技術的應用前景十分廣闊,從醫學問答、疾病預測或是醫學影像分析,都有巨大的潛力。
期待在未來,Hugging Face將持續發揮其關鍵作用,不斷推動人類與技術之間的互動,並為信息獲取和內容創作等領域的創新和變革,為世界帶來更多的智慧和進步。

更多精彩內容:
更多資訊及參考資料:
[1] The Open Medical-LLM Leaderboard: Benchmarking Large Language Models in Healthcare,Hugging face,2024.04.19